Last month, I was given an assignment to attend a workshop with one of our clients. The workshop, as it was called, turned into something more like a hackathon, with various groups attempting to POC some concepts. The big talk of the workshop was micro services.
If you are not familiar with micro services, you should take a look at Martin Fowler’s article. The idea behind micro services is simple. You take an application (which might be a service) and then break it down into smaller, very focused services.
As an example, consider eCommerce. You have online store, which uses a service to handle the various actions required for a customer to order items and have them shipped and tracked. If you examine this from a micro-services perspective, you will separate out the customer shopping cart, order processing, fulfillment and tracking into different services. As you dig deeper you might even go further.
In this entry, I want to dig into micro services a bit deeper, from a Microsoft .NET perspective, but I first want to give some foundation to the micro services concept by understanding how we got here in the first place. That is the main focus of this entry, although I will talk about a high level implementation and some pros and cons.
NOTE: For this article, as with most of my posts, I will define the word “application” as a program that solves a business problem. From this definition, it should not matter how the application interacts with users, and you should not have to rewrite the entire application to create a different presentation (for example, windows to web). I use define the word “solution” as a particular implementation of an application or applications.
Foundations
When we first learn to create applications, the main focus is on solving the problem. This is most easily accomplished by creating a single executable that contains all of the code, which is commonly called a monolith (or monolithic application).
TBD
Monoliths are most often considered bad these days, but there are pluses and minuses to every approach. With the monolith, you have the highest performance of any application type, as everything runs in a single process. This means there is no overhead marshalling across application processes spaces. There is also no dealing with network latency. As developers often focus on performance first, the monolith seems to get an unfair amount of flack. But there are tradeoffs for this level of performance.
- The application does not scale well, as the only option for scale is vertical. You can only add so many processors and so much memory. And hardware only runs so fast. Once you have the most and fastest, you are at maximum scale.
- There is a reusability issue. To reuse the code, you end up copying and pasting to another monolith. If you find a bug, you now have to fix it in multiple applications, which leads to a maintainability issue.
To solve these issues, there is a push to componentizing software and separating applications into multiple services. Let’s look at these two topics for a bit.
Componentizing for Scale (and Reusability)
While the monolith may work fine in some small businesses who will never reach a scale that will max out their monolith, it is disastrous for the Enterprise, especially the large Enterprise. To solve this “monolith problem”, there have been various attempts at componentizing software. Here are a list of a few in the Microsoft world (and beyond):
COM: COM, or the Component Object Model is Microsoft’s method for solving the monolith problem. COM was introduced in 1993 for Windows 3.1, which was a graphical shell on top of DOS. COM was a means of taking some early concepts, like Dynamic Data Exchange (DDE), which allowed applications to converse with each other, and Object Linking and Embedding (OLE), which was built on top of DDE to allow more complex documents by embedding types from one document type into another. Another common word in the COM arena is ActiveX, which is largely known as an embedding technology for web applications that competed with Java applets.
DCOM and COM+: DCOM is a bit of a useless word, as COM was able to be distributed rather early on. It was just hard to do. DCOM, at its base level, was a set of components and interfaces that made communication over Remote Procedure Call (RCP) easier to accomplish. DCOM was largely in response to the popularity of CORBA as a means of distributing components. COM+ was a further extension of DCOM which allowed for distributed transactions and queueing. COM+ is a merger of COM, DCOM libraries and Microsoft Transaction Server (MTS) and the Microsoft Message Queue service (MSMQ).
.NET: If you examine Mary Kirtland’s early articles on COM+ (one example here), you will read about something that sounds a lot like .NET is today. It is designed to be easily distributed and componentized. One problem with COM+ was DLL Hell (having to clean out component GUIDs (globally unique identifiers) to avoid non-working applications). .NET solved this by not registering components and returning to the idea of using configuration over convention (a long fight that never ends?).
Competing technologies in this space are EJB and RMI in the Java world and CORBA and the CCM as a more neutral implementation. They are outside of the scope of this document.
The main benefit of technologies are they make it easier to reuse code, reducing maintainability, and allow you to more easily distribute applications, providing greater availability and scalability. You can still choose to build monolithic applications, when they make sense, but you are not tied to the limitations of the monolith.
Services
One issue with many of the component technologies was they tightly coupled the consumer to the application, or the “client” to the “server”. To get away from this, a group of developers/architects at Microsoft came up with SOAP (Yes, I know Don Box was actually working for DevelopMentor as a contractor at Microsoft and Dave Winer was heading UserLand software and only partnering with Microsoft on XML and RPC communication, but the majority of the work was done there). With the creation of SOAP, we now had a means of creating applications as services, or discrete applications, which could focus on one thing only. That is sounding a lot like micro services … hmmmm.
In the Microsoft world, SOAP was used to create “web services”. The initial release of .NET in 2002 allowed one to create services using HTTP and SOAP as ASMX services (a type of document in ASP.NET) as well as create faster RPC type services with Remoting (generally these were internal only, as it was hard to play with them outside of the Enterprise, due primarily to more tight coupling to technologies, much less play with them outside of the Microsoft world).
By 2006, with the release of .NET 3.0, Microsoft had merged the concepts of Remoting and ASMX web services in the Windows Communication Foundation (WCF). You could now develop the service and add different endpoints with ease, allowing for an RCP implementation and a web implementation off the same service. WCF really came to fruition about a year later with the release of .NET 3.5.
The latest service technology to enter the fray is Representational State Transfer (REST). In the Microsoft world, REST was first introduced in REST toolkit, an open source project. From the standpoint of an official Microsoft release, it was released as the WCF Web API. It was a bit kludgy, as WCF works in a completely different paradigm than REST, so the project was moved over the web group and is now implemented on top of ASP.NET MVC as the ASP.NET Web API.
Methodologies, Technologies and Tools
One more area we should look at before moving to micro services are methodologies, technologies and tools used to solve the monolith “problem”.
Methodologies
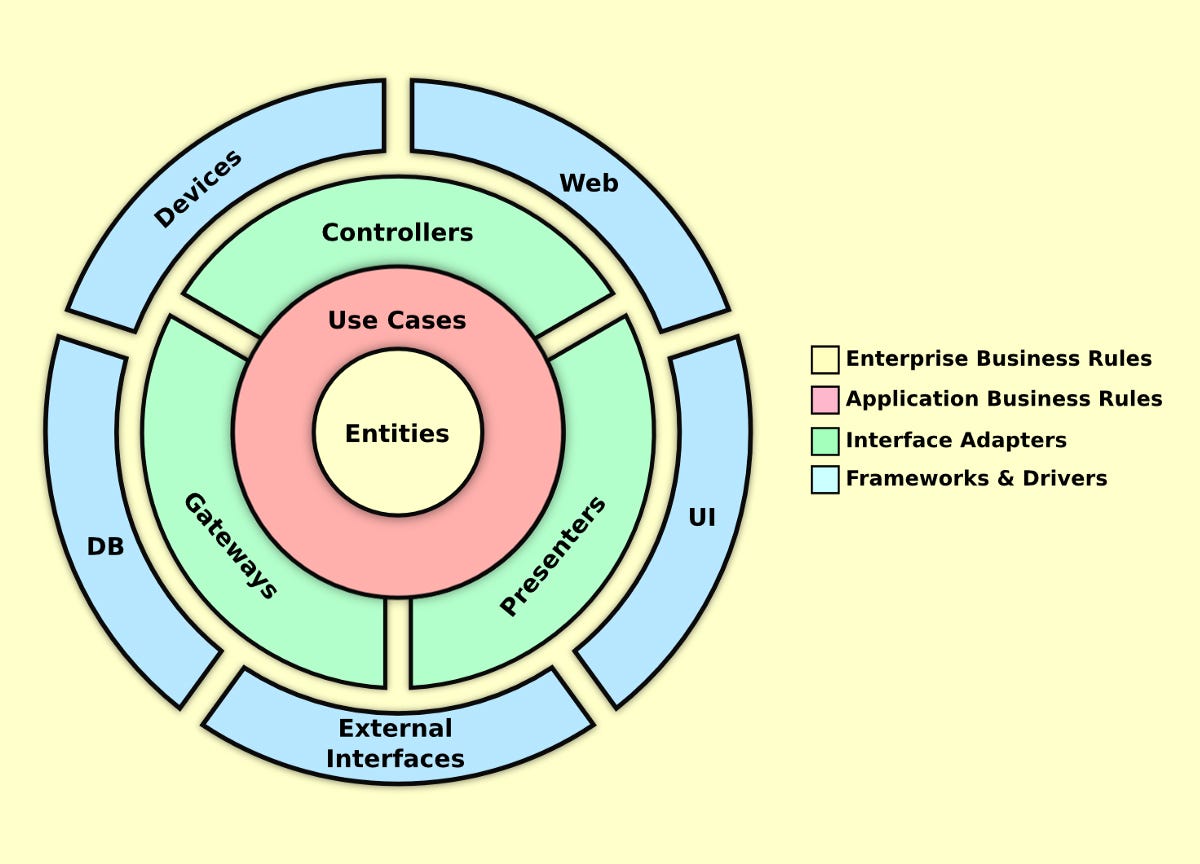
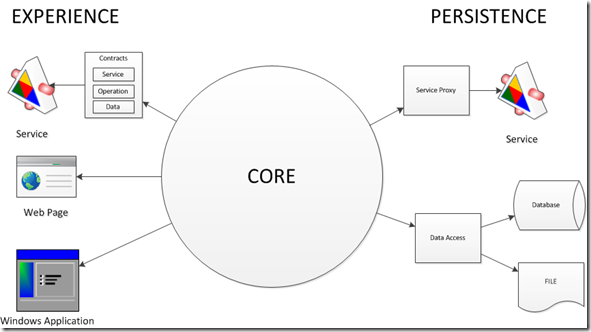
The first methodology that gained a lot of acceptance in the Microsoft world was the n-tier development methodology. The application was divided into UI, Business and Data tiers (note: today Microsoft calls this Presentation, Middle and Data tiers), with the push towards separating out the functionality into discrete, purposed pieces. Below is a typical n-tier diagram for an application.
Around 2010, I realized there was a problem with n-tier development. Not so much with the methodology, as it was sound, but with the way people were viewing the models. Below is an n-tier model of an application:

The issue here is people would see an application as the merger of presentation, business logic and data. Is this true? Let’s ask a couple of questions.
1. If you create a web application with the exact same functionality as a windows application is it 2 applications or one? In implementation, it was often treated as two, but if it was logically and physically two applications, you were duplicating code.
2. If you want to add a web service to expose the functionality of the application, do you rebuild all n tiers? If so, should you?
My view is the application is the part that solves business problems, or the core of the functionality. You should be able to change out where you persist state without changing this functionality. I think most people understand this as far as switching out one database server for another, like SQL Server to Oracle. When we get to the logical level, like changing out schemas, a few get lost here, but physical switches with the same schema is well known and most find it easy to implement. Switching out presentation is what most people find more difficult, and this is generally due to introducing logic other than presentation logic in the presentation portion of the solution.
NOTE: The naming of the tiers in 3-tier and n-tier architecture has changed over time. Originally, it was common to see UI, Business and Data. The illustration above calls the tiers Client, Middle and Data. I have also seen Presentation, Application and Persistence, which is closer to the naming I would use in my models.
To better illustrate this concept, in 2010 I came up with a methodology called Core as Application (seen in this article on the importance of domain models). In this model the core libraries ARE the application. The libraries for presentation can easily be switched out, and have responsibility for shaping the data for presentation.

The “Core as Application” model requires you start with your domain models (how data is represented in the application) and your contracts, both for presentation and persistence. Some of the benefits of this model are:
- Focusing on domain models and contracts first pushes the team to plan before developing (no, there is no surefire way to force people other than tasers ;->). This is a good representation no matter what methodology or model you use, but it is critical if you are going to have multiple teams working on different parts of a solution.
- You can have multiple teams working in parallel rather than relying on completing one layer prior to working on another. You will have to resynchronize if any team determines the contract needs to be changed, but the amount of rework should be minimal.
When you look at “Core as Application” from a SOA standpoint, each service has its own core, with a service presentation layer. The persistence for higher level applications is the individual services. This will be shown a bit later.
Technologies
We have already covered some technologies used to solve the monolith problem. COM and .NET are good examples. But as we move even deeper, we find technologies like the ASP.NET Web API is useful. The technologies do not force us to not create monoliths, as even Microsoft pushes out some examples with data access, as LINQ to SQL, in a controller in an MVC application. But they do get us thinking about creating cohesive libraries that serve one purpose and classes that give us even more fine grained functionality.
Tools
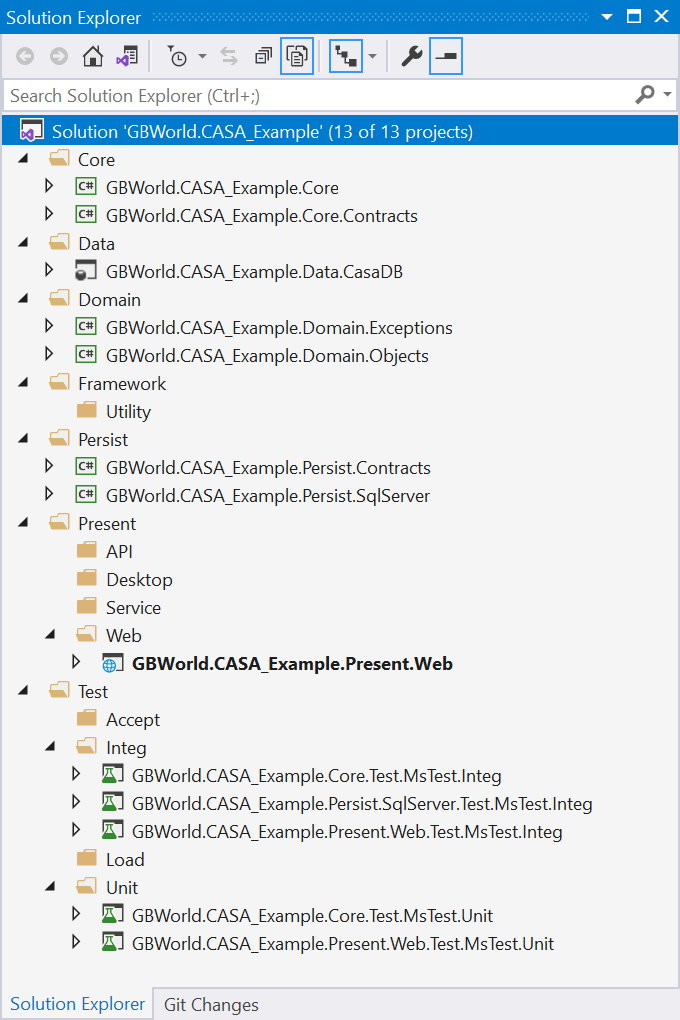
We also have tools at our service. Visual Studio helps us organize our code into solutions and projects. The projects focus on a more fine grained set of functionality, helping us break the monolith up. If we follow best practices, our solutions end up with more projects, which can easily be broken down into individual micro services. Speaking of which, this a good time to segue.
Onward to Micro Services
Micro services are being presented as something new, but in reality, they are nothing more than Service Oriented Architecture (SOA) taking to the nth degree. The idea behind micro services is you are going extremely fine grained in your services. It is also stated you should use REST, but I don’t see REST as an absolute requirement. Personally, I would not aim for SOAP as there is a lot of extra overhead, but it is possible to use SOAP in micro services, if needed. But I digress … the first question to answer is “what is a micro service?”
What is a Micro Service?
I am going to start with a more “purist” answer. A micro service is a small service focused on solving one thing. If we want to be purist about it, the micro service will also have its own dedicated database. If we were to illustrate the order system example we talked about earlier, using the “Core as Application” model, the micro-services implementation would be something like the picture below.

If you want to take it to an extreme, you can view micro services the way Juval Lowy viewed in 2007 (video gone, but you can read the description). His idea was every single class should have a WCF service on top of it. Doing so would create a highly decoupled system possible, while maintaining a high level of cohesiveness. Micro services does not dictate this type of extreme, but it does recommend you find the smallest bounded context possible. I will suggest a practical method of doing this a bit later.

One difference between Juval Lowy’s suggested “one service per class” and micro services is the suggested service methodology has changed a bit. In 2007, WCF was focused on SOAP based services. Today, REST is the suggested method. Technically, you can develop a micro service with SOAP, but you will be adding a lot of unnecessary overhead.
Below are Martin Fowler’s characteristics of a micro service:
· Componentization via services – This has already been discussed a bit in the previous two paragraphs. Componentization is something we have done for quite some time, as we build DLLs (COM) or Assemblies (.NET – an assembly will still end in .DLL, but there is no Dynamic Link Library capability for COM inherently built in without adding the Interop interfaces). The main difference between an assembly (class library as a .dll file) and a micro service is assembly/dll is kept in process of the application that utilizes it while the micro-service is out of process. For maximum reuse, you will build the class library and then add a RESTful service on top using the ASP.NET Web API. In a full micro services architecture, this is done more for maintainability than need.
· Organized around business capabilities – This means you are looking for bounded contexts within a capability, rather than simply trying to figure out the smallest service you can make. There are two reasons you may wish to go even smaller in micro services. The first, and most reasonable, is finding a new business capability based on a subset of functionality. For example, if your business can fulfill orders for your clients, even if they are not using your eCommerce application, it is a separate business capability. A second reason is you have discovered a piece of functionality can be utilized by more than one business capability. In these cases, the “business capability” is internal, but it is still a capability that has more than one client. Think a bit more about internal capabilities, as it may make sense to duplicate functionality if the models surrounding the functionality are different enough a “one size fits both (or all)” service would be difficult to maintain.
- Product Not Projects – This means every service is seen as a product, even if the only consumer is internal. When you think of services as products, you start to see the need for a good versioning strategy to ensure you are not breaking your clients.
- Smart Endpoints and dumb pipes – I am not sure I agree completely with the way this one is worded, but the concept is the endpoint has the smarts to deliver the right answer and the underlying delivery mechanism is a dumb asynchronous message pump.
- Decentralized Governance – Each product in a micro services architecture has its own governance. While this sounds like it goes against Enterprise concepts like Master Data Management (MDM), they are really not opposites at all, as you will see in the next point
- Decentralized Data Management – This goes hand in hand with the decentralized governance, and further illustrates the need for Master Data Management (MDM) in the organization. In MDM, you focus on where the golden record is and make sure it is updated properly if a change is needed. From this point on, the golden record is consulted whenever there is a conflict. In micro services, each micro service is responsible for the upkeep of its own data. In most simple implementations, this would mean the micro service contains the golden record. If there are integrated data views, as in reporting and analytics, you will have to have a solution in place to keep the data up to date in the integrated environment.
- Infrastructure Automation – I don’t see this a mandatory step in implementing micro services, but it will be much harder if you do not have automation. This topic will often start with Continuous Integration and Continuous Delivery, but it gets a bit deeper, as you have to have a means of deploying the infrastructure to support the micro service. One option bandied about on many sites is a cloud infrastructure. I agree this is a great way to push out microservices, especially when using cloud IaaS or PaaS implementations. Both VMware and Microsoft’s Hyper-V solutions provide capabilities to easily push out the infrastructure as part of the build. In the Microsoft world, the combination of the build server and release management are a very good start for this type of infrastructure automation. In the Linux world, there is a tool called Docker that allows you to push out containers for deployment. This capability also finds its way to the Microsoft world in Windows Server 2016.
- Design For Failure – Services can and will fail. You need to have a method of detecting failures and restoring services as quickly as possible. A good application should have monitoring built in, so the concept is nothing new. When your applications are more monolithic, you more easily determine where you problem is. In micro services, monitoring becomes even more critical.
- Evolutionary Design – I find this to be one of the most important concepts and one that might be overlooked. You can always decompose your micro services further at a later date, so you don’t have to determine the final granularity up front. As a micro service today can easily become an aggregator of multiple micro services tomorrow, There are a couple of concepts that will help you create your microservices we will discuss now: Domain Driven Design and Contract First Development.
Domain Driven Design
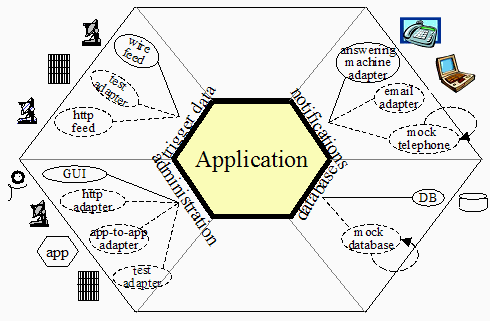
Domain Driven Design (DDD) is a concept formulated by Eric Evans in 2003. One of the concepts of DDD that is featured in Fowler’s article on micro services is the Bounded Context. A bounded context is the minimum size a service can be broken down into and still make sense. Below is a picture from Fowler’s article on Bounded Contexts.
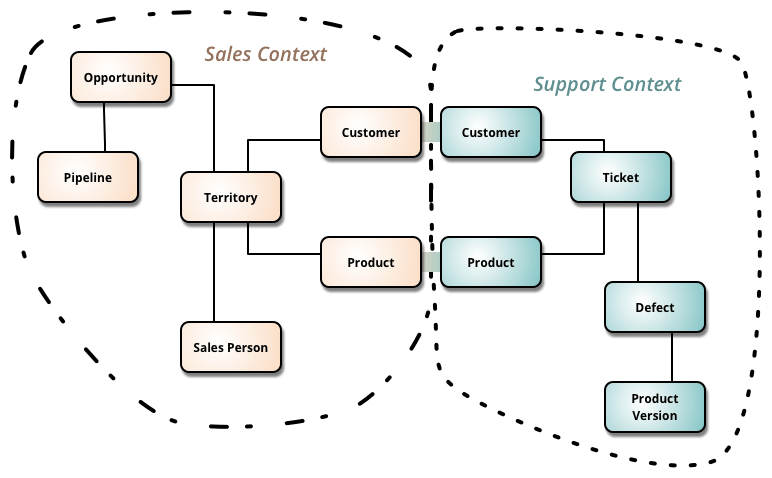
When you start using DDD, you will sit down with your domain experts (subject matter experts (SMEs) on the domain) and find the language they use. You will then create objects with the same names in your application. If you have not read Eric Evans Domain Driven Design book, you should learn a bit about modeling a domain, as it is a process to get it right.
NOTE: you are not trying to make your data storage match the domain (ie, table names matching domain object names); let your database experts figure out how to persist state and focus on how the application uses state to create your domain objects. This is where Contract First comes into play.
Contract First Development
Once you understand how your objects are represented in your domain, and preferably after you have a good idea of how the objects look in your presentation projects and your data store, you can start figuring out the contracts between the application, the presentation “mechanism” and the persistent stores.
In general, the application serves its objects rather than maps them to presentation objects, so the contract focuses on exposing the domain. The presentation project is then responsible for mapping the data for its own use. The reason for this is presenting for one type of presentation interface will force unnecessary mapping for other types. As an example, I have seen n-tier applications where the business layer projects formatted the data as HTML, which forced writing an HTML stripping library to reuse the functionality in a service. Ouch!
How about the persistence “layer”? The answer to this question really depends on how many different applications use the data. If you are truly embracing micro services, the data store is only used by your service. In these cases, if storage is different from the domain objects, you would still desire spitting out the data shapes that fit the domain objects.
How to Implement Microsoft Services, High Level
Let’s look at a problem that is similar to something we focused on for a client and use it to determine how to implement a micro services architecture. We are going to picture an application for an Human Resources (HR) services company that helps onboard employees We will call the company OnboardingPeople.com (and hope it is not a real company?).
Any time a new employee comes on board there is a variety of paperwork that needs to be completed. In the HR world, some of the forms have a section that is filled out by the employee and another that is filled out by a company representative. In the micros services application architecture, we might look at creating a micro service for the employee portion and another for the employer portion. We now have a user facing application that has two roles and uses the two services to complete its work. Each service surrounds a bounded context that focuses on a single business capability.

Over time, we start working with other forms. We find the concept of an employee is present in both of the forms and realize employee can now represent a bounded context. The capability may only be internal at this time, so there is a question whether it should be separated out. But we are going to assume the reuse of this functionality is a strong enough reason to have a separate capability. There is also a possibility the employer agent can be separated out (yes, this is more contrived, but we are envisioning where the solution(s) might go).

If we take this even further, there is a possibility we have to deal with employees from other country, which necessitates an immigration micro service. There are also multiple electronic signatures needed and addresses for different people, so these could be services.

In all likelihood, we would NEVER break the solution(s) into this many micro services. As an example, addresses likely have a slightly different context in each solution and are better tied to services like the employee service and employer services rather than a separate service that is able to keep context
Pros and Cons
While micro services are being touted in many articles as THE solution for all applications, silver bullets don’t exist, as there are no werewolves to kill in your organization. Micro services can solve a lot of pain points in the average Enterprise, but there is some preparation necessary to get there and you need to map it out and complete planning before implementing (I will focus on another article to go into more detail on implementation).
Pros
One of the main pros I see mentioned is the software is the right size with micro services. The fact you are implementing in terms of the smallest unit of business capability you can find means you have to separate the functionality out so it is very focused. This focus makes the application easier to maintain. In addition, a micro services architecture naturally enforces tight cohesion and loose coupling. Another benefit is you naturally have to develop the contract up front as you are releasing each service as a discreet product.
You also have the flexibility to choose the correct platform and language on a product by product (service by service) basis. The contract has to be implemented via standards for interoperability, but you are not tied into single technology. (NOTE: I would still consider limiting the number of technologies in use, even if there is some compromise, as it gets expensive in manpower having to maintain multiple technologies).
Micro services will each be in control of their own data and maintain their own domains. The small nature of the services will mean each domain is easy to maintain. It is also easier to get a business person focused on one capability at a time and “perfect” that capability. It goes without saying micro services work well in an Agile environment.
Micro services architecture also allows you the ability to scale each service independently. If your organization has adopted some form of cloud or virtual infrastructure, you will find it much easier to scale your services, as you simply add additional resources to the service.
Cons
Micro services is a paradigm shift. While the concepts are not radically different, you will have to force your development staff to finally implement some of the items they “knew” as theory but had not implemented. SOLID principles become extremely important when implementing a micro services architecture. If your development methodologies and staff are not mature enough, it will be a rather major paradigm shift. Even if they are, a shift of thinking is in order, as most shops I have encountered have a hard time viewing each class library as a product (Yes, even those who have adopted a package manager technology like NuGet).
There is a lot of research that is required to successfully implement a micro services architecture.
· Versioning – You can no longer simply change interfaces. You, instead, have to add new functionality and deprecate the old. This is something you should have been doing all along, but pretty much every developer I have met fudges this a good amount of the time. It is internal, so I can fix all of the compiler errors, no problem. This is why so many shops have multiple solutions with the same framework libraries referenced as code. You should determine your versioning strategy up front.
· URI Formatting – I am assuming a REST approach for your micro services when I include URI formatting, but
· API Management – When there are a few services, this need will not be as evident. As you start to decompose your services in to smaller services, it will become more critical. I would consider some type of API management solution, like Layer 7 (CA), Apigee, or others, as opposed to building the API management or relying on an Excel spreadsheet or internal app to remind you to set up the application correctly.
· Instrumentation and Monitoring – Face it, most of us are bad at setting the plumbing, but it becomes critical to determine where an error occurs in a micro services architecture. In theory, you will know where the problem is, because it is the last service deployed, but relying on this idea is dangerous.
· Deployment – As with the rest of the topics in this section, there is a lot of planning required up front when it comes to deployment. Deployment should be automated in the micro services world. But deployment is more than just pushing applications out, you need to have a rollback plan if something goes wrong. In micro services, each service has its own deployment pipeline, which makes things really interesting. Fortunately, there are tools to help you with build and release management, including parts of the Microsoft ALM server family, namely build server and release management.
In short, micro services are simple to create, but much harder to manage. If you do not plan out the shift, you will miss something.
Summary
This is the first article on micro services and focuses on some of the information I have learned thus far. As we go forward, I will explore the subject deeper from a Microsoft standpoint and include both development and deployment of services.
Peace and Grace,
Greg
Twitter: @gbworld